
記事公開日
【商標調査最前線コラムシリーズ第7回】AIは商標調査の救世主か? ~文字商標の商標調査、商標検索のAI化における技術的課題

みなさん、こんにちは! IP-RoBoの岩原です。
私の執筆論文(※)に基づいて、商標調査を取り巻く長年の課題、そしてそれを解決するかもしれないAIへの期待について、シリーズを追って見てきました。前回の第6回では、AIが商標調査の効率化や質の向上に貢献するのではないか、という期待について述べました。
しかし、どんなに有望なテクノロジーであっても、その実用化には乗り越えなければならない壁が存在します。今回は、商標調査AI、特に文字商標調査をサポートするAIの実現に向けた技術的な課題について、具体的に掘り下げていきたいと思います。そこには、期待だけでは見えてこない、データの側面における厳しい現実が存在します。
(※)技術情報協会「“知財DX”の導入と推進ポイント」401頁(2025年4月30日発刊)(https://www.gijutu.co.jp/doc/b_2292.htm)
前回配信した「AIは商標調査、商標検索の救世主となるか? ~長年の課題解決に向けたテクノロジーへの期待~」もぜひご一読ください。
商標調査最前線コラムシリーズに関する解説動画が、知財オンラインにて公開されています。ぜひ下記リンクからご視聴ください。
解説動画:https://www.youtube.com/watch?v=wxi1ioaQDP0
<目次>
AI(機械学習)に必要な「学習データ」の条件
現在のAI技術の中心である機械学習が有効に機能し、十分な精度を出すためには、少なくとも以下の2つの条件を満たすことが基本的に必要と考えられます。
(1) 学習データが大量に用意できること
(2) 学習データが十分な信頼性を有していること
では、商標調査の分野、特にAIによる文字商標の類否判断において、これらの条件は満たされているのでしょうか。
残念ながら、商標分野におけるデータの特性がAI活用の技術的な課題となっています。
技術的課題①:桁違いに不足する学習データ
文字商標の類否判断をAIに学習させる上で、最も深刻な課題の一つが、圧倒的な学習データの不足です。

(1) 称呼類否判断のデータ不足
称呼(呼び方)の類否判断は、単に文字が似ているかどうかだけでなく、異なる部分の前後の音、異なる部分が称呼全体の中でどの位置にあるか、称呼全体の長さなど、様々な要因を考慮して判断されます。この複雑な判断をAIに学習させるためには、「あらゆる2つの称呼間の類否判断」を学習データとして用意することが理想となります。 しかし、これは現実的ではありません。例えば、仮に称呼に出てくる音を日本語の50音に限定し、さらに比較対象をわずか4文字の称呼どうしに絞った場合(例えば、「ライオン」と「ライアン」の類否判断)、生じうる称呼の組み合わせ総数は50の4乗で625万通りとなります。そして、この2つの称呼の組み合わせ全体における類否判断を網羅するためには、なんと 50の4乗 × 50の4乗 = 約39兆通りもの類否判断データが必要になります。
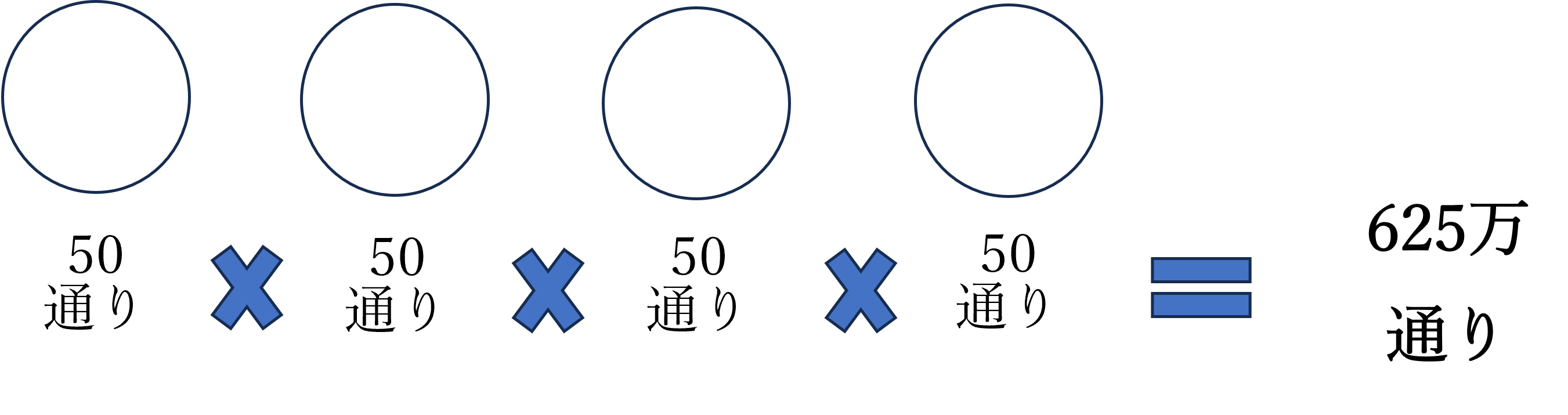 ▲ 4文字称呼で生じる組合せ総数
▲ 4文字称呼で生じる組合せ総数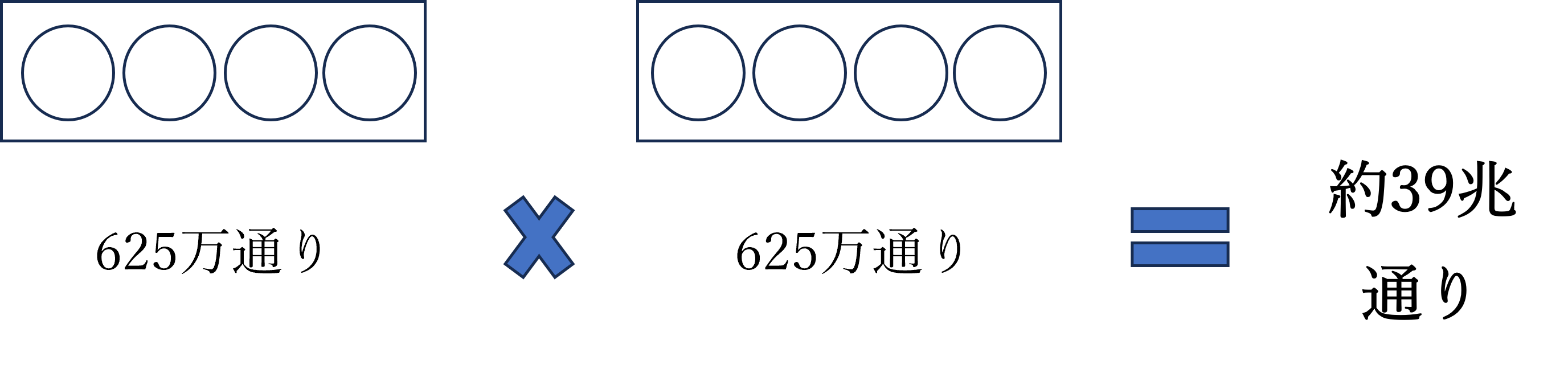 ▲ 4文字称呼どうしを比較する際の組合せ数(理想的な必要データ数)
▲ 4文字称呼どうしを比較する際の組合せ数(理想的な必要データ数)
これに対して、これまで特許庁が出した審決はせいぜい数万件、審査段階の判断を加えてもせいぜい数百万件程度にすぎません。これは、たった4文字の称呼類否をAIに学習させるために必要とされる約39兆通りというデータ量と比較すると、検討すること自体憚られるほどの桁違いに不足していると言わざるを得ません。さらに、5文字以上の称呼や、文字数が異なる称呼の類否判断となると、必要なデータ量はさらに膨らみ、学習データの不足はより深刻になります。
文字結合商標調査に関する記事はこちら
≫ 商標調査、商標検索、さらなる難関! ~「長い名前」をどう調べる? プロも悩む文字結合商標の壁~
(2) 文字結合商標における要部認定のデータ不足
複数の文字を組み合わせた文字結合商標の称呼類否判断では、単に全体の称呼を類否だけでなく、商標の中で最も重要となる部分(要部)を認定する判断が極めて重要になります。 どの部分が要部となるかは、その語がどのような商品や役務に使用されるかによって識別力(他の商品やサービスと区別できる力)の強さが変わるため、あらゆる語と商品・役務の組み合わせにおける識別力を判断した学習データが必要となります。例えば、広辞苑第七版に収録されている約25万語に対し、現在特許庁で登録が認められている商品・役務の区分である約1万種類を前提とすると、その組み合わせは 約25億通りにもなります。理想的には、これらの組み合わせ全てについての識別力判断データが必要となります。 しかし、上記で述べたように、審決等のデータ総数はこれに遠く及ばないだけでなく、さらに識別力判断がなされているのはごく一部の審決等に限られています。このため、文字結合商標の処理に不可欠な要部認定をAI化するために必要な学習データも、圧倒的に不足しているのが現状です。
このように、称呼類否判断においても、文字結合商標の要部認定においても、AIに十分な精度で学習させるために必要なデータ量は膨大であるにもかかわらず、実際に利用可能な公的な判断データは極めて限定されており、根本的に学習データが不足していることが大きな技術的課題となっています。
技術的課題②:学習データの信頼性欠如
AIに学習させるべきデータが「十分な信頼性」を有しているかという点も、商標の類否判断においては難しい課題となります。
理想的には、特定の2つの称呼の類否判断は、専門家であれば誰が行っても、いつ行っても、共通した結論になるべきです。しかし、現実には、商標を巡る紛争が多数発生していることからも明らかなように、異なる専門家間で類否判断が異なることは日常的に生じています。さらに、驚くべきことに、同一の専門家であっても、判断する時期が異なれば、異なる判断を下すことも珍しくありません。
最も信頼されるべき判断とされる、特許庁の審査や審決、あるいは裁判所の判決でさえも、完全ではありません。審査での判断が審決で覆されたり、審決が裁判所の判決で否定されたり、さらには地方裁判所の判決が知的財産高等裁判所の判決で否定されるといったことは、制度的に想定されていることであり、実際に頻繁に発生しているのが実態です。これは、特許庁、裁判所、あるいは商標専門の弁理士といった専門家の称呼類否判断でさえも、完全に統一的で揺るぎないものではないことを示唆しています。
加えて、称呼類否判断の基準そのものも、固定不変のものではなく、社会状況や知的財産権を巡る政策によって変化しうる性質を持っています。このことも、過去の判断データを一律に、絶対的な「正解」として扱うことの難しさ、すなわち学習データの信頼性に関わる課題となります。
このように、AIに学習させるべき「正解」データであるはずの専門家による判断データ自体が、ある程度のばらつきや不確実性を含んでおり、これをそのままAIに学習させた場合に、どこまで安定した、信頼できる判断が可能になるのか、という根本的な信頼性の課題が存在します。
まとめ データの壁は厚い
前回のコラムで商標調査におけるAI活用への大きな期待について述べましたが、今回の分析で明らかになったのは、その期待を実現する上で避けられない「データの壁」です。必要な学習データが圧倒的に不足している点、そしてその限られたデータでさえ、完全に統一的で信頼できるものとは言えない点。これらの技術的な課題は、文字商標の類否判断という、商標調査の根幹に関わるAIの開発を非常に難しくしています。
AIは魔法の杖ではありません。その能力は、学習データの量と質に大きく依存します。現在の商標類否判断に関するデータの状況を見る限りでは、AIが単独で、あるいは専門家と同等以上の精度で類否判断を行うレベルに到達するには、まだ相当な技術開発と、場合によってはデータ蓄積の仕組みそのものの改善が必要であると考えられます。
次回は、図形類否調査のAI化における技術的課題についても、掘り下げていきたいと思います。
≪関連記事はこちら≫
次回(第8回):8月下旬公開予定
前回(第6回):AIは商標調査、商標検索の救世主となるか? ~長年の課題解決に向けたテクノロジーへの期待~
******************************************************************
[ 執筆者 プロフィール ]
岩原 将文 /株式会社IP-RoBo CEO 弁護士
主として、特許、著作権その他の知的財産権に関する相談、契約、訴訟等を行う。
大学・大学院時代には、機械学習に関する研究を行っていた。
<関連リンク>
WEB:https://ip-robo.co.jp/
お問い合わせ:info@ip-robo.co.jp またはお問い合わせフォームから
******************************************************************


