
記事公開日
最終更新日
【商標調査最前線コラムシリーズ第2回】商標調査、商標検索、なぜそんなに大変なの? ~「似ているか」を見分けるプロの悩み~

みなさん、こんにちは! IP-RoBoの岩原です。
このコラムシリーズでは、大切なビジネスの「顔」である「商標」について、私が執筆した「商標調査におけるAI活用の問題点および可能性」(※)に基づいて、わかりやすくお話していきます。
前回の第1回では、商標が何か、そして商標権を取るためには「商標調査」がとっても大事だよ、というお話をしましたね。特に、これから使いたい商標が、すでに他の誰かに登録されていないか、「似ているか似ていないか(類否)」を調べることが重要だとご紹介しました。
今回は、その商標調査、特に「似ているか」を見分ける類否調査が、なぜそんなに大変なのか? 知的財産のプロでさえ頭を悩ませる、その課題に迫ってみたいと思います。
※技術情報協会「“知財DX”の導入と推進ポイント」401頁(2025年4月30日発刊)(https://www.gijutu.co.jp/doc/b_2292.htm)
前回配信した「ビジネスの「顔」を守る!はじめての商標調査」もぜひご一読ください。
<目次>
- 商標調査の二つの顔 ~文字と図形~
- DBサービスの商標検索の限界 ~「正確な検索」と「あいまいな検索」
- DBサービスの称呼検索の落とし穴 ~多すぎるヒットと、判断の難しさ~
- 結局、最後は「人の目と経験」頼み
- さらに増える「見るべき件数」~人間の限界を超えて~
- まとめ 経験頼りの商標調査は限界に近付いている
商標調査の二つの顔
~文字と図形~
まずおさらいですが、商標調査には、文字でできている商標を調べる「文字類否調査」と、ロゴマークなどの図形を含む商標を調べる「図形類否調査」の主に二つがあります。
現在の類否調査は、「J-PlatPat」等のDBサービスを利用して商標検索によって行われていますが、既存のDBサービスには大きな課題があります。
DBサービスの商標検索の限界
~「正確な検索」と「あいまいな検索」~
文字商標を既存DBサービスで調べるとき、たいてい二つの検索方法が用意されています。一つは、漢字やひらがな等、見たままの文字を入力して検索する方法(商標検索)。もう一つは、商標の「呼び方(称呼)」を入力して検索する方法(称呼検索)です。
さて、あなたが調べたい商標が、例えば「駿馬」という文字だったとしましょう。
既存DBサービスの商標検索 は、「駿馬」という文字と完全に一致するか、またはその文字を部分的に含んでいるか、という検索にしか対応していません。
これでは、「駿馬」という同じ読み方だけど「shunme」のように別の文字種(ここでは、アルファベット)を使っている商標や、同じ文字種であっても異なる文字を使った「旬芽」のような商標を見つけ出すことができません。
つまり、「似ている」商標を探すのには、この方法だけでは全然不十分なのです。
そこで登場するのが 既存DBサービスの称呼検索です。「駿馬」の読み方である「シュンメ」と入力して検索します。この方法だと、多くの既存DBサービスで字体等は違うけれど称呼が同じ商標として、「shunme」や「旬芽」を検索することができます。
更に、既存DBサービスの称呼検索の中でも類似検索を使うと、称呼が一部異なっていても似ている称呼である「SUNME」(称呼は、「スンメ」)や「春夢」(称呼は「シュンム」)を検索することができます。
文字類否調査をする際には、この称呼検索(類似検索)を使うのが一般的です。
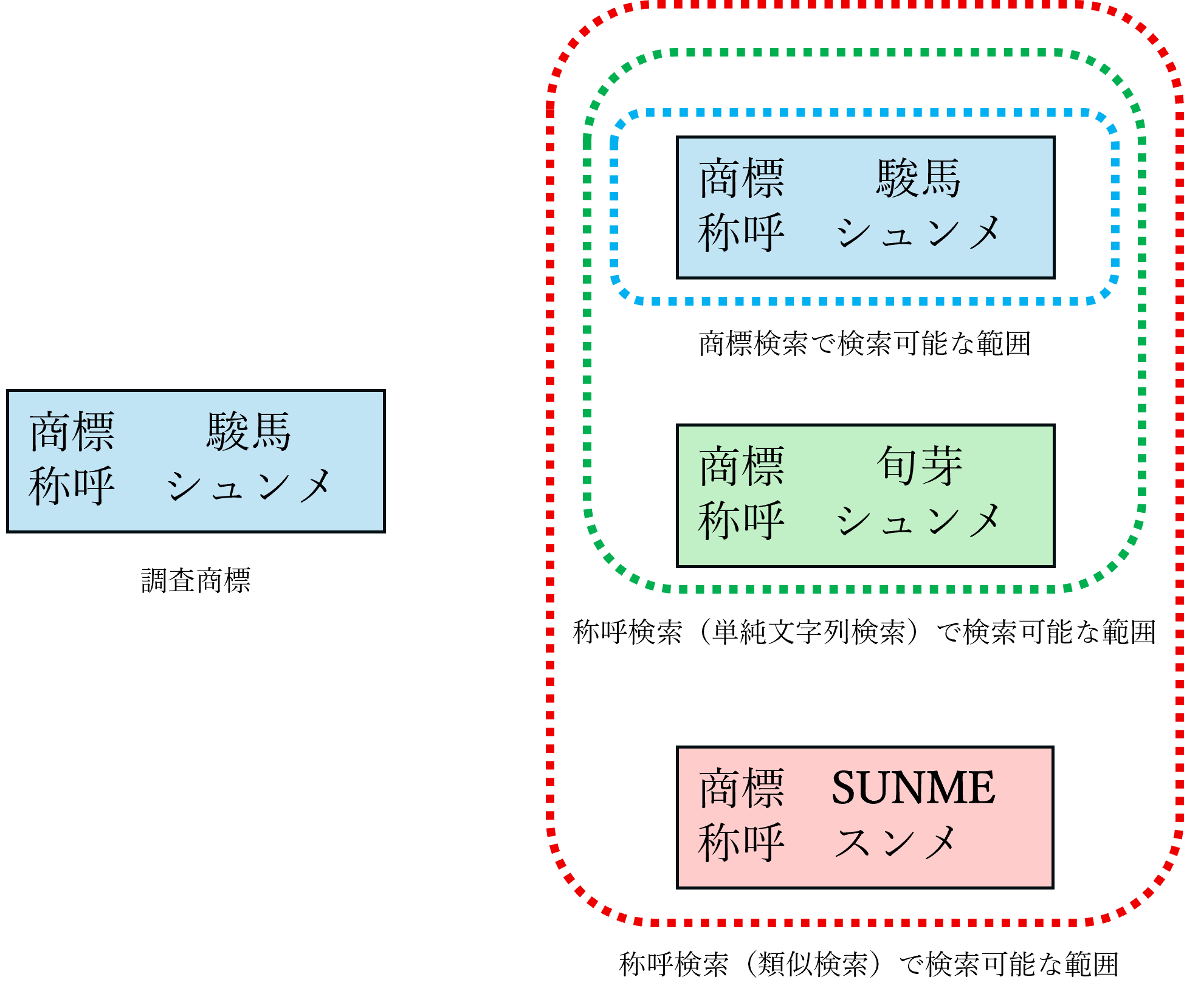
▲既存DBサービスにおける各検索方法とヒット範囲
DBサービスの称呼検索の落とし穴
~多すぎるヒットと、判断の難しさ~
「それなら称呼検索を使えば大丈夫そうかな?」と思いますよね。ところが、ここに既存DBサービスにおける大きな課題があります。
既存DBサービスの称呼類似検索は、例えば「1音だけ違うもの」「2音だけ違うもの」といった、あらかじめ決められた一定のルールに基づいて機械的に検索を行うことが一般的です。
これはコンピュータには得意なことですが、人間の感覚とは少しずれることがあります。
その結果、何が起こるかというと… 「ん? これ、全然似てなくない?」という登録商標まで、大量にヒットしてしまうことが日常的に発生してしまうのです。
例えば、「シュンメ」で検索したのに、「ギュンメ」とか「ガシュンメン」といった、ルール上はヒットするけれど、商標として「似ているか」と聞かれると首をかしげてしまうような商標がたくさん表示されてしまいます。
しかも、DBの提供する情報では、なぜその商標がヒットしたのか(どのルールに引っかかったのか)は教えてくれても、「そのヒットした商標が、あなたが調べたい商標と、どれくらい似ているか?」という「類似性の度合い」を示す指標(類似指標)を正確に算出したり、似ている順に並べ替えたりすることは、原理的に難しいのです。
結局、最後は「人の目と経験」頼み
これが、既存DBサービスを使った商標調査が大変な最大の理由です。
称呼検索で大量にヒットした商標の中から、「これは本当に似ているから注意が必要だ」という商標を一つ一つ、自分の専門的な知識と長年の経験に基づいて判断していく作業が、調査者には避けられないのです。
商標の「似ているか似ていないか」の判断は、単に文字や音が一致するかだけでなく、見た目の印象、呼び方、意味合い、さらには商品やサービスの種類との関連性など、様々な要素を総合的に考慮する、非常に専門性が高く、熟練した勘が必要な作業です。
だからこそ、商標のプロ(弁理士や知的財産部の方など)でないと、既存DBサービスを使って商標調査を自分で行うこと自体が極めて難しい状態になっているのです。商品開発部の方が「ちょっと自分で調べてみよう」と思っても、どこまで調べれば十分なのか、ヒットした結果をどう判断すればいいのか、途方に暮れてしまうでしょう。
さらに増える「見るべき件数」
~人間の限界を超えて~
追い打ちをかけるように、最近は既存DBサービスが「調査の抜け漏れを防ぐ」という目的で、一度の検索で表示される最大ヒット件数をどんどん増やしています。
例えば、無料のDBサービス「J-PlatPat」では、2019年に1回の検索の最大ヒット件数が1,000件から3,000件に、2025年にはなんと30,000件にまで引き上げられました。
想像してみてください。一度の検索で最大30,000件もの商標が表示され、その一つ一つについて「これは自分が調べたい商標と似ているかな?大丈夫かな?」と、正確に判断していく膨大な作業・・・。
これはもはや、人間の能力の限界を超えていると言わざるを得ません。
このような状況では、もはや何らかのシステム的なサポートがなければ、十分な質を保った商標調査を行うこと自体が現実的ではなくなってきているのです。

▲J-PlatPatの1検索あたりの最大ヒット件数の推移と、調査者の負担
まとめ
経験頼りの商標調査は限界に近付いている
今回は、商標調査、特に文字の類否調査がなぜ大変なのか、その裏側にある既存DBサービスの課題や、プロの調査者にかかる大きな負担について見てきました。
大量にヒットする結果の中から、人間の目と経験だけを頼りに「本当に似ている」商標を見つけ出す作業が、いかに時間と労力のかかる、そして限界が近づいている作業か、お分かりいただけたかと思います。
次回は、実務的に重要でありながら調査難易度が更に高い「文字結合商標」の調査についてみていきます。
≪関連記事はこちら≫
次回(第3回):商標調査、商標検索、さらなる難関! ~「長い名前」をどう調べる? プロも悩む文字結合商標の壁~
前回(第1回):ビジネスの「顔」を守る!はじめての商標調査
******************************************************************
[ 執筆者 プロフィール ]
岩原 将文 /株式会社IP-RoBo CEO 弁護士
主として、特許、著作権その他の知的財産権に関する相談、契約、訴訟等を行う。
大学・大学院時代には、機械学習に関する研究を行っていた。
<関連リンク>
WEB:https://ip-robo.co.jp/
お問い合わせ:info@ip-robo.co.jp またはお問い合わせフォームから
******************************************************************


